▼本日は、JRA-VANのデータマイニングについて、当研究所の見解を書いてみたいと思います。
まず、結論から書いていきます↓
・データマイニングとは、大量のデータを分析し、競馬の結果をあらかじめ予測するモデルのこと
・データマイニングは、単純に指数上位馬を購入しても勝てない。マイニング上位馬の単純回収率は70~80%程度しかない
・データマイニングの活用法としては、人気との乖離を狙うのが基本
・あるいは、データマイニング単体で馬券購入するのではなく、他のロジックと組み合わせて使うのが有効
ではこの根拠について、具体的に解説していきましょう。

▼JRA-VANの有名な指数に、「データマイニング」というものがあります。
データマイニング(Data Mining)とは、コンピュータがデータ分析して、レース結果を事前に予測するモデルのこと。
つまり、コンピュータ予測ですね。
天気予報や、経済予測、株価予測もコンピュータで行われますが、それの競馬版がデータマイニングです。
「マイニングとは、鉱山などで鉱脈から採掘すること。データの山から人間にとって有意義な情報を発掘することをたとえて、データマイニングと言われるようになりました」
JRAのサイトより引用
▼要するに、競馬の結果をコンピュータに予想させようというのが、データマイニングです。
マイニングでは、コンピュータがあらかじめ予想した順位が表示されます。
では、このデータマイニングを活用して、利益を出すことはできるのか?
▼私自身も、過去に実際にデータマイニングで馬券を買い続けてみたことがあります。
その経験から言うと、「データマイニングだけで利益を出すのは難しい」と感じました。
というか、単純にマイニング上位の馬を買うなどの戦略で競馬に勝つ事は、ほぼ不可能と言えます。
▼なぜ優秀なコンピュータが予想した順位が、実際の馬券で役に立たないのか?
それは、「コンピュータが期待値を考えていないから」だと思います。
▼コンピュータは、膨大なデータの中から有効なファクターだけを抽出し、そこから順位を予想しています。
あくまでも、「過去のデータからは、このパターンの馬が上位に来やすい」という予測であり、「この馬が儲かる」という予測ではないわけです。
なので、データマイニング上位馬の成績はまずまずなんですが、回収率はマイナスになってしまうわけですね。
記事後半では、実際にデータマイニングを活用した結果や回収率についても解説していきたいと思います。
競馬の年間収支をプラスにするサイトを公開
▼競馬ファンの最終目標である「年間プラス収支」
これを達成するためには、馬券知識を身につけるしかない。
私が、年間プラス収支を達成できたのは、
やっぱり⇒『このユニークなサイト』で学んだからです。

データマイニングの結果と回収率
▼ということで、マイニングについて、次の解説をしていきましょう。
先程の続き。
データマイニングは、コンピュータが上位に来やすい馬を予測している指数であり、期待値は考えられていない。
なので、データマイニング上位馬は、好走確率は高いが、回収率はプラスにはならない。
▼では実際に、データマイニング上位馬の回収率について分析してみましょう。
【データマイニング。順位別の単勝回収率】2020~2023年
76(%)
80
74
82
80
75
74
68
74
63
70
66
66
62
69
55
34
35
(※上からマイニング1~18位)
はい。
過去3年半のすべてのレースにおいて、データマイニングの順位別の単勝回収率を集計すると、上記のようになります。
▼このデータを見るとわかるように、マイニング上位馬の単勝馬券を買い続けても、余裕でマイナス収支になることがわかります。
マイニング1位の単勝馬券を買い続けると、回収率は76%になる。
ごく普通の回収率ですね。むしろ単勝馬券の還元率80%を考えると、平均より少し低いくらいです。
▼同様に、マイニング2位は単勝回収率80%。マイニング3位は単勝回収率74%となっています。
マイニング上位馬の単勝馬券を買い続けても、全く儲からないわけです。
この理由が、先ほどから書いている通り、「マイニングは、期待値を考慮していないから」なんですね。
▼競馬というのは、強い馬を購入しても儲かりません。
競馬で儲かる仕組みというのは、「強いけど人気がない馬」を買うことで、期待値が歪み、そこから利益が生まれるわけです。
なので、単純に来る確率が高い馬を表示しているデータマイニングは、そのロジック単体では、利益を出すのは難しいわけです。
▼そこで、マイニングで利益を出すためのコツ・活用法として、「マイニング指数と人気との乖離を狙う」というものがあります。
これは要するに、「マイニング上位だけど、人気がない馬」を狙うということです。
こうすることによって、期待値が高い馬を購入することができます。
▼例えば、「マイニング1位で、9~10番人気の馬」は、複勝回収率が87~94%程度あります。
単純に、マイニング1位の単勝を買い続けた場合と比べて、回収率が一気に上がっているのが分かります。
このように、人気と指数との乖離を狙うことが、データマイニング必勝法に近づくヒントになるわけですね。
▼▼「指数と人気の乖離を狙う」という戦略は、馬券で利益を出すために、超有効なロジックになります。
これはデータマイニングだけでなく、スピード指数でも、調教指数でも、能力指数でも、あらゆる指数で有効な戦略です。
私の馬券収支は、年間でプラス収支になっていますが、そんな私の基本戦略は、指数と人気の乖離を狙うパターンです。
▼もし、単純に強い馬だけを探したいのであれば、このような「乖離狙い」は必要ありません。
しかし、私たちが馬券を購入する目的は、強い馬を探すためではなく、馬券で儲けるためです。
馬券で儲けるためには、単純に指数上位の馬を購入していてはダメなんです。
▼マイニング上位馬は、データ的に条件が揃っている馬と言えます。
なので、好走確率はそれなりに高くなる。
そのような条件を抽出するのは、コンピュータの得意分野だからです。
▼しかし、コンピュータは条件に合致したデータを抽出するのは得意だけれども、データを並列に処理して、そこから利益を生むという作業は、苦手なんですね。
だから、株でも他のギャンブルでも、コンピュータに運用させると、あまりうまくいかないわけです。
▼ただ、コンピューター予想が全くの無意味というわけではありません。
コンピューター予想に完全に乗っかってしまうのは危険だけれども、コンピュータの予想を人間が分析して利用すれば、それは有効なロジックになります。
コンピュータが得意な部分はコンピュータに任せて、実際にそれを活用するのは人間の頭脳とする。
このように役割分担することで、データマイニングで利益を出すことができるようになります。
▼このような考え方は、馬券で利益を出すために必須の考え方になります。
例えば、調教やパドックを見る場合でも、「単純に気配が良い馬」を購入しても利益は出ない。
しかし、「気配が良いのに、人気がない馬」を購入すれば、利益を出しやすくなるわけです。
▼馬券というのは、他の競馬ファンとの戦いなので、常にオッズをチェックし続ける必要があります。
どんな指数も、データマイニングも、調教データも、オッズと比較することで、そこに優位性が生まれてくる。
なので、「人気と指数を比較する」という作業を常に意識していけば、あなたの馬券収支は飛躍的に向上するわけですね。
▼▼では次に、「データマイニング単体で馬券購入するのではなく、他のロジックと組み合わせて使う」ということについて。
ここまで書いてきた通り、データマイニングはそれなりに有効な指数なんですが、マイニング上位の馬を購入するだけでは利益を出すことはできません。
利益を出すためには、「マイニング指数と人気との乖離を狙う」か、あるいは「マイニング指数と他のロジックを組み合わせる」という作業が必要になります。
▼マイニング指数と他のロジックを組み合わせる、というのは、例えばマイニングと調教を組み合わせるとか、マイニングと他のスピード指数を組み合わせる、ということです。
ということで、マイニングと、どのようなロジックを組み合わせると効果的かを、少し列挙してみましょう。
【マイニングと組み合わせると有効なロジック】
他のスピード指数
調教
パドック
PCの競馬ソフトでのデータ分析
展開を読む
内枠を狙う(ダートは外枠を狙う)
逃げ馬・先行馬を狙う
前走1着を狙う
前走1番人気を狙う
トップジョッキーを狙う
はい。
マイニング単体では利益を出せなくても、上記のようなロジックと組み合わせることで、利益を出すことができるようになります。
▼まず、「他のスピード指数」と組み合わせる。
世の中には、マイニング指数だけでなく、数多くのスピード指数が存在しています。
これらのスピード指数を、マイニング指数と組み合わせることによって、威力がアップし、回収率をプラスにできる可能性が高くなるわけです。
マイニング指数もスピード指数も、それ単体では利益を出すことは難しいわけですが、組み合わせることによって利益を出せるようになるわけですね。
▼例えば、「マイニング1位と、スピード指数1位が合致している馬を軸として馬券を構成する」などの戦略が考えられます。
あるいは、「一番人気から三番人気のうち、マイニング指数上位かつ、スピード指数上位の馬を軸にする」という戦略も有効ですね。
マイニングが1位でスピード指数も1位というのは、データ的に好走の条件が揃っているということなので、期待値が高くなりやすいわけです。
なので、このような条件が揃った馬が出現するまでレースを見送り続けて、出現したら、そこで満を持して勝負をかける。
このようなスタンスで馬券購入することによって、マイニングで回収率をプラスにできる可能性が高くなるわけですね。
こちらの記事も読まれています↓
 競馬 短距離戦で強い血統は?芝ダート別データ。種牡馬と距離適性の関係。回収率が高い儲かる血統
競馬 短距離戦で強い血統は?芝ダート別データ。種牡馬と距離適性の関係。回収率が高い儲かる血統 G1レース・重賞レースで強い騎手は?大きなレースで儲かる騎手データ。勝率・連対率・複勝率・回収率
G1レース・重賞レースで強い騎手は?大きなレースで儲かる騎手データ。勝率・連対率・複勝率・回収率 ハイペースとスローペースで有利な脚質は?タイムの基準は何秒?逃げ先行差し追い込みどれを買うか
ハイペースとスローペースで有利な脚質は?タイムの基準は何秒?逃げ先行差し追い込みどれを買うか 木幡巧也騎手のデータ傾向と特徴。回収率・勝率・連対率。重賞・G1成績と狙い目。上手い騎手の現在。同期
木幡巧也騎手のデータ傾向と特徴。回収率・勝率・連対率。重賞・G1成績と狙い目。上手い騎手の現在。同期 競馬で回収率100%を超える買い方。馬券でプラス収支にする方法。回収率を上げるコツと儲かるポイント
競馬で回収率100%を超える買い方。馬券でプラス収支にする方法。回収率を上げるコツと儲かるポイント 横山武史騎手のデータ傾向と特徴。回収率と勝率と連対率。成績一覧と狙い目
横山武史騎手のデータ傾向と特徴。回収率と勝率と連対率。成績一覧と狙い目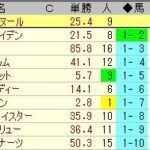 競馬で回収率の高い買い方は?的中率と利益率が高い馬券構成。回収率を上げる方法
競馬で回収率の高い買い方は?的中率と利益率が高い馬券構成。回収率を上げる方法 国分恭介騎手のデータ傾向と特徴。回収率・勝率・連対率。重賞・G1成績と狙い目
国分恭介騎手のデータ傾向と特徴。回収率・勝率・連対率。重賞・G1成績と狙い目 高齢馬の重賞での勝率・回収率データ。7歳馬・8歳馬のG1成績。歳をとった馬は弱い?馬券の狙い目
高齢馬の重賞での勝率・回収率データ。7歳馬・8歳馬のG1成績。歳をとった馬は弱い?馬券の狙い目 牡馬と牝馬はどっちが強い?牝馬が弱い理由。ダートは牝馬が弱い?牝馬の狙い目と違い
牡馬と牝馬はどっちが強い?牝馬が弱い理由。ダートは牝馬が弱い?牝馬の狙い目と違い
